Dithering is used in computer graphics to create the illusion of "color depth" in images with a limited color palette - a technique also known as
color quantization. In a dithered image, colors that are not available in the palette are approximated by a diffusion of colored pixels from within the available palette. The human eye perceives the diffusion as a mixture of the colors within it. Dithered images, particularly those with relatively few colors, can often be distinguished by a characteristic graininess or speckled appearance. For example,
dithering might be used in order to display a photographic image containing millions of colors on a video hardware that is only capable of showing
256 colors at a time. The
256 available colors would be used to generate a dithered approximation of the original image. Without
dithering, the colors in the original image might simply be "rounded off" to the closest available color, resulting in a new image that is a poor representation of the original. So I will try to present different methods designed to perform
dithering...
Thresholding :
 |
| "Averaging" grey level method used and n = 100 |
With the
thresholding, you just have to convert your image in
grey level with the method of your choice which explains the presence of the parameter
style in the following source code example (here are the different
methods we already saw) and then one pixel component value of every pixels (the
Red, the
Green or the
Blue one because the
grey level of a pixel always verifies
Red=
Green=
Blue) must be compared against a fixed threshold
n ranging from
0 to
255 that will determine the final color,
Black or
White. This may be the simplest
dithering algorithm there is, but it results in immense loss of detail and contouring as you can see on my illustration above.
Random dithering :
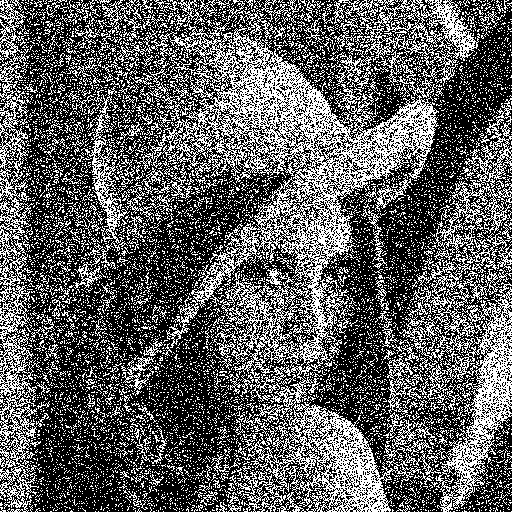 |
| "Averaging" grey level method used |
Random dithering was the first attempt (at least as early as 1951) to remedy the drawbacks of
thresholding. After converting your image in
grey level, each pixel must be compared against a certain random threshold ranging from
0 to
255, resulting in a staticky image. Although this method doesn't generate patterned artifacts, the noise tends to swamp the detail of the image. It is analogous to the practice of mezzotinting.
Average dithering :
Average dithering is very similar to the
thresholding method but this time, the threshold
n at which all pixels are compared will depend on the image you want to process. It means that this threshold must be calculated from your input image and it is called the
AOD (
Average Optical Density). To get this value, convert your image in
grey level, get the
histogram of the resulting image (I assume you know how to create a
histogram of the
grey level which was explained
here). Finally, the
AOD is just the average intensity level of this
histogram. The illustrations above show the result of the
average dithering with the use of exactly
8 different
grey level styles.
Floyd-Steinberg dithering :
 |
| "Averaging" grey level method used and n = 127 |
The
Floyd-Steinberg algorithm (published in 1976 by Robert W. Floyd and Louis Steinberg), like many other
dithering algorithms, is based on the use of
error diffusion. This method works as follows. Each pixel in the original image is thresholded (as we saw with the
thresholding method) and the difference between the original pixel value and the thresholded value is calculated. This is what we call the error value. This error value is then distributed to the neighboring pixels that haven’t been processed yet according to a certain diffusion filter :
The pixel indicated with a star (*) indicates the pixel currently being scanned, the blank pixels are the previously-scanned pixels, the pixels indicated with dots (...) are the pixels not affected by the error diffusion when processing the current pixel and the coefficients represent the proportion of the error value which is distributed (added) to the neighboring pixels of the current one.
Note that it exists an algorithm specially called the
False Floyd-Steinberg algorithm providing poorer results and which can be applied with this diffusion filter where
X is now the current pixel :
 |
| "Averaging" grey level method used and n = 127 |
X (3/8)
(3/8) (1/4) ...
Jarvis, Judice, and Ninke dithering :
 |
| "Averaging" grey level method used and n = 127 |
The Jarvis, Judice, and Ninke dithering (developed in 1976) is coarser, but has fewer visual artifacts. As you can see, the task is a bit more fastidious. Indeed, the quantization error must now be transfered to exactly 12 neighboring pixels.
X (7/48) (5/48)
(1/16) (5/48) (7/48) (5/48) (1/16)
(1/48) (1/16) (5/48) (1/16) (1/48)
Stucki dithering :
 |
| "Averaging" grey level method used and n = 127 |
The Stucki dithering (a rework of the Jarvis, Judice, and Ninke filter developed by P. Stucki in
1981) is slightly faster and its output tends to be clean and sharp.
X (4/21) (2/21)
(1/21) (2/21) (4/21) (2/21) (1/21)
(1/42) (1/21) (2/21) (1/21) (1/42)
Burkes dithering :
 |
| "Averaging" grey level method used and n = 127 |
Burkes dithering (developed by Daniel Burkes of TerraVision in 1988) is a simplified form of Stucki dithering that is faster, but is less clean than Stucki dithering.
X (1/4) (1/8)
(1/16) (1/8) (1/4) (1/8) (1/16)
Sierra dithering (the
3 existing)
:
"Averaging" grey level method used and n = 127
Sierra dithering (developed by Franckie Sierra in 1989) is based on Jarvis dithering, but it's faster while giving similar results.
X (5/32) (3/32)
(1/16) (1/8) (5/32) (1/8) (1/16)
... (1/16) (3/32) (1/16) ...
Two-row Sierra is the above method, but was modified by Sierra to improve its speed.
X (1/4) (1/16)
(1/16) (1/8) (3/16) (1/8) (1/16)
Filter Lite is an algorithm by Sierra that is much simpler and faster than Floyd–Steinberg, while still yielding similar results (and according to Sierra, better).
X (1/2)
(1/4) (1/4) ...
Atkinson dithering :
 |
| "Averaging" grey level method used and n = 127 |
Atkinson dithering was developed by
Apple programmer Bill Atkinson, and resembles
Jarvis dithering and
Sierra dithering, but it's faster. Another difference is that it doesn't diffuse the entire
quantization error, but only three quarters. It tends to preserve detail well, but very light and dark areas may appear blown out.
X (1/8) (1/8)
(1/8) (1/8) (1/8) ...
... (1/8) ... ...
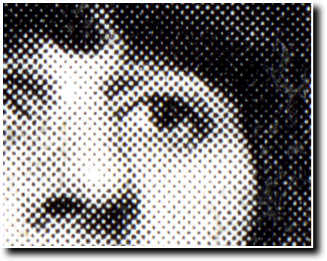
Ordered threshold :
 |
| Who is he/she? |
-
Halftone effect with
dots
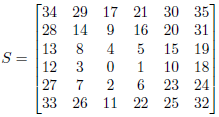 |
Note that the values of this threshold matrix are very low and consequently this will change most of the pixels of your image into the white color if they are directly thresholded by each value of S as there is a bigger probability that your pixel values are higher than all these ones on a color scale ranging from 0 to 255 (unless your image is totally dark).
So you must replace the values of S by (x * 255) / 35 where x is a value of this threshold matrix
(or else, each (y * 35) / 255 can also be simply thresholded by x where y is a pixel component value!) |
With the ordered threshold method, instead of using a fixed threshold for the whole image (or random values for each pixel), a threshold matrix (named S here) of a predefined pattern is applied. The matrix paved over the image plane and each pixel of the image is thresholded by the corresponding value of the matrix. To apply the ordered threshold method, you must create a filter of the same size as your image by replicating the threshold matrix S on both directions as many times as possible (then by filling each extra columns/rows). It's the most difficult part of the processing because the dimensions of the threshold matrix S may or NOT divide the dimensions of your image. Finally, you just have to follow the thresholding method but with your new created filter. Note that I separately applied the thresholding method for each (Red,Green,Blue) pixel components so that the image is still in color (even if there are only 23 types of color now as a pixel component value can be only 0 or 255). The threshold matrix S above can be used to obtain a halftone effect with dots (see illustration) and the get_dots function (line 2) just returns the threshold matrix S as it is defined.
-
Halftone effect with
squares
This new threshold matrix S can be used to obtain a halftone effect with squares (see illustration) using again the ordered threshold method (like with all the following filters). The only differences to take in count are the new dimensions of S : 5x5 and its new values.
-
Central white point
 |
| Same remark that the one previously evoked with the halftone effect |
-
Balanced centered point
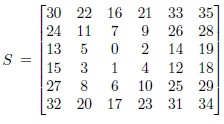 |
| Same remark that the one previously evoked with the halftone effect |
-
Diagonal ordered matrix with balanced centered points
|
Same remark that the one previously evoked with the halftone effect but this time
the values of S1 must be replaced by (x * 255) / 15 and the values of S2 by (x * 255) / 31
where x is a value of S1 or S2.
(or else, each (y * 15) / 255 for S1 or (y * 31) / 255 for S2 can also be simply thresholded by x where y is a pixel component value) |
-
Dispersed dots or
the Bayer filter
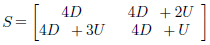 |
| Same remark that the one previously evoked with the halftone effect |
Hope you ❤ this post!

















































{kind=link}